在 Kubernetes 的 GPU 支持的实现里,kubelet 实际上就是将GPU 设备目录和GPU 驱动目录,设置在了创建该容器的 CRI (Container Runtime Interface)参数里面。这样,等到该容器启动之后,对应的容器里就会出现 GPU 设备和驱动的路径了。
Kubernetes 在 Pod 的 API 对象里,并没有为 GPU 专门设置一个资源类型字段,而是使用了一种叫作 Extended Resource(ER)的特殊字段来负责传递 GPU 的信息。
在 Kubernetes 的 GPU 支持方案里,并不需要真正去做上述关于 Extended Resource 的这些操作。在 Kubernetes 中,对所有硬件加速设备进行管理的功能,都是由一种叫作 Device Plugin 的插件来负责的。这其中,当然也就包括了对该硬件的 Extended Resource 进行汇报的逻辑。
下图展示了Device Plugin 机制:
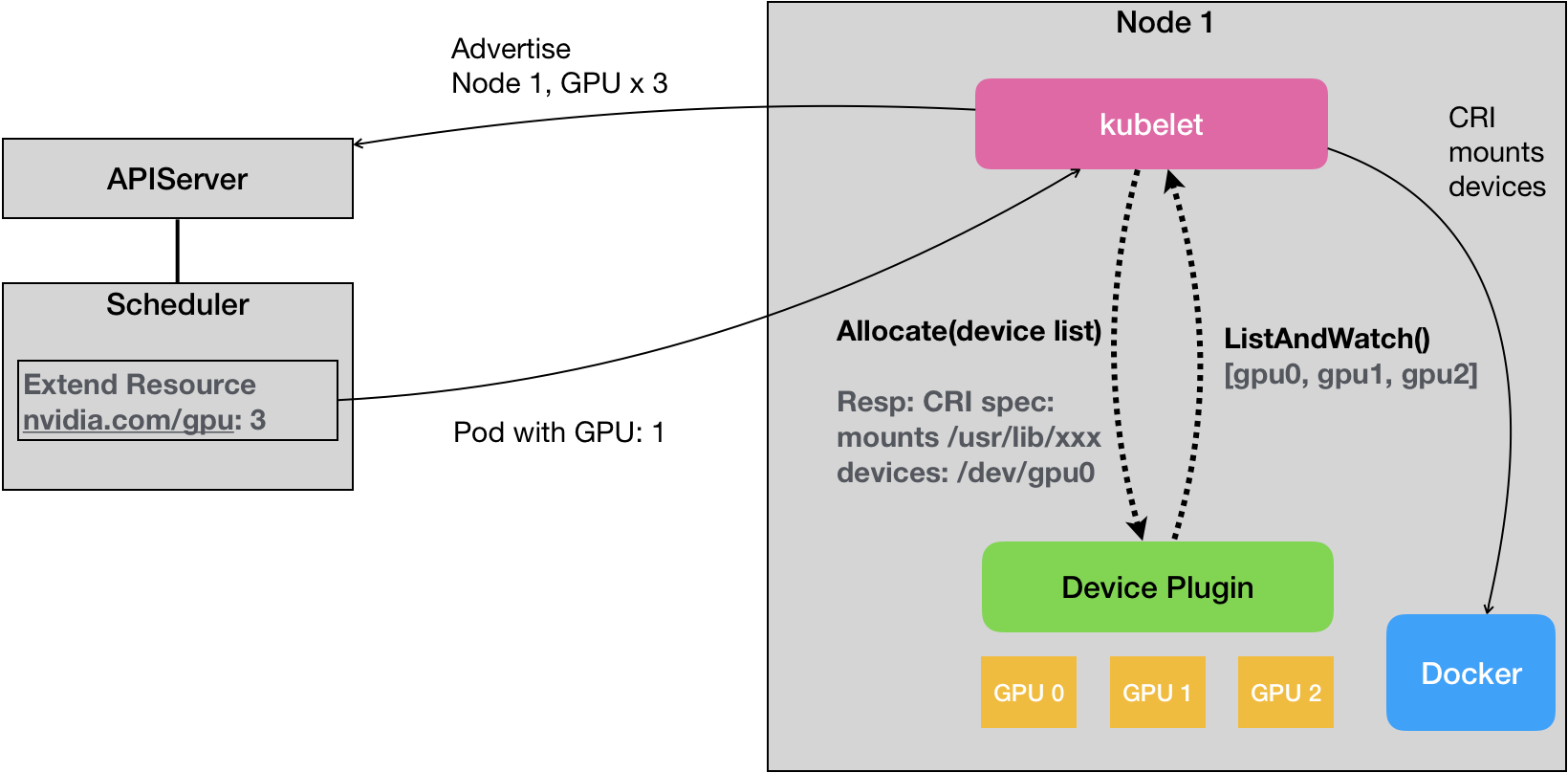
对于每一种硬件设备,都需要有它所对应的 Device Plugin 进行管理,这些 Device Plugin,都通过 gRPC 的方式,同 kubelet 连接起来。
右侧开始看起,这个 Device Plugin 会通过一个叫作 ListAndWatch 的 API,定期向 kubelet 汇报该 Node 上 GPU 的列表。ListAndWatch 向上汇报的信息,只有本机上 GPU 的 ID 列表,而不会有任何关于 GPU 设备本身的信息。而且 kubelet 在向 API Server 汇报的时候,只会汇报该 GPU 对应的 Extended Resource 的数量。kubelet 本身,会将这个 GPU 的 ID 列表保存在自己的内存里,并通过 ListAndWatch API 定时更新。当一个 Pod 想要使用一个 GPU 的时候,在 Pod 的 limits 字段声明nvidia.com/gpu: 1。Kubernetes 的调度器就会从它的缓存里,寻找 GPU 数量满足条件的 Node,然后将缓存里的 GPU 数量减 1,完成 Pod 与 Node 的绑定。
这个调度成功后的 Pod 信息,自然就会被对应的 kubelet 拿来进行容器操作。而当 kubelet 发现这个 Pod 的容器请求一个 GPU 的时候,kubelet 就会从自己持有的 GPU 列表里,为这个容器分配一个 GPU。此时,kubelet 就会向本机的 Device Plugin 发起一个 Allocate() 请求。这个请求携带的参数,正是即将分配给该容器的设备 ID 列表。
当 Device Plugin 收到 Allocate 请求之后,它就会根据 kubelet 传递过来的设备 ID,从 Device Plugin 里找到这些设备对应的设备路径和驱动目录。当然,这些信息,正是 Device Plugin 周期性的从本机查询到的。比如,在 NVIDIA Device Plugin 的实现里,它会定期访问 nvidia-docker 插件,从而获取到本机的 GPU 信息。
被分配 GPU 对应的设备路径和驱动目录信息被返回给 kubelet 之后,kubelet 就完成了为一个容器分配 GPU 的操作。接下来,kubelet 会把这些信息追加在创建该容器所对应的 CRI 请求当中。这样,当这个 CRI 请求发给 Docker 之后,Docker 为你创建出来的容器里,就会出现这个 GPU 设备,并把它所需要的驱动目录挂载进去。

