Operator 的工作原理,利用了 Kubernetes 的自定义 API 资源(CRD),来描述我们想要部署的“有状态应用”;然后在自定义控制器里,根据自定义 API 对象的变化,来完成具体的部署和运维工作。
Etcd Operator
使用 Helm Chart 部署 etcd 集群
1 | # 1. 添加 Bitnami Helm 仓库 |
部署完成后实际上是在 Kubernetes 里添加了一个名叫 EtcdCluster 的自定义资源类型。而 Etcd Operator 本身,就是这个自定义资源类型对应的自定义控制器。
Etcd Operator 部署 Etcd 集群,采用的是静态集群(Static)的方式。
静态集群的好处是,它不必依赖于一个额外的服务发现机制来组建集群,非常适合本地容器化部署。而它的难点,则在于你必须在部署的时候,就规划好这个集群的拓扑结构,并且能够知道这些节点固定的 IP 地址。
Etcd Operator集群具体的组建过程是逐个节点动态添加的方式,即:
首先,Etcd Operator 会创建一个“种子节点”;
然后,Etcd Operator 会不断创建新的 Etcd 节点,然后将它们逐一加入到这个集群当中,直到集群的节点数等于 size。
这就意味着,在生成不同角色的 Etcd Pod 时,Operator 需要能够区分种子节点与普通节点。
而这两种节点的不同之处,就在于一个名叫–initial-cluster-state 的启动参数:
- 当这个参数值设为 new 时,就代表了该节点是种子节点。种子节点还必须通过–initial-cluster-token 声明一个独一无二的 Token。
- 而如果这个参数值设为 existing,那就是说明这个节点是一个普通节点,Etcd Operator 需要把它加入到已有集群里。
Etcd Operator 启动要做的第一件事( c.initResource),是创建 EtcdCluster 对象所需要的 CRD
接下来,Etcd Operator 会定义一个 EtcdCluster 对象的 Informer。
Etcd Operator 并没有用工作队列来协调 Informer 和控制循环。
在控制循环里执行的业务逻辑,往往是比较耗时间的。比如,创建一个真实的 Etcd 集群。而 Informer 的 WATCH 机制对 API 对象变化的响应,则非常迅速。所以,控制器里的业务逻辑就很可能会拖慢 Informer 的执行周期,甚至可能 Block 它。而要协调这样两个快、慢任务的一个典型解决方法,就是引入一个工作队列。
Etcd Operator 在业务逻辑的流程图如下:
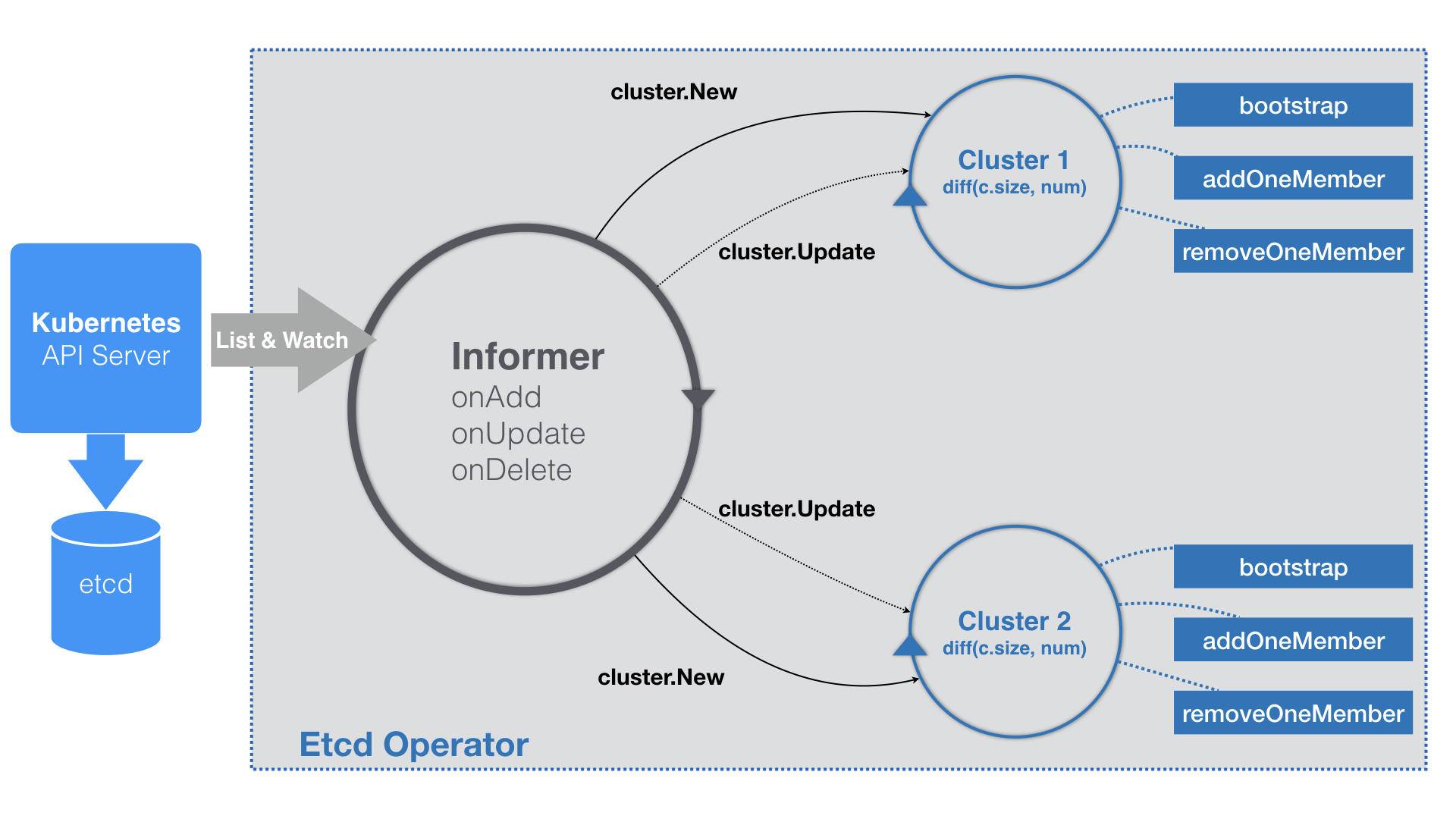
Etcd Operator 的特殊之处在于,它为每一个 EtcdCluster 对象,都启动了一个控制循环,“并发”地响应这些对象的变化。这种做法不仅可以简化 Etcd Operator 的代码实现,还有助于提高它的响应速度。
当YAML文件第一次被提交到 Kubernetes 之后,Etcd Operator 的 Informer,就会立刻“感知”到一个新的 EtcdCluster 对象被创建了出来。所以,EventHandler 里的“添加”事件会被触发。
而这个 Handler 要做的操作也很简单,即:在 Etcd Operator 内部创建一个对应的 Cluster 对象(cluster.New),比如流程图里的 Cluster1。
这个 Cluster 对象,就是一个 Etcd 集群在 Operator 内部的描述,所以它与真实的 Etcd 集群的生命周期是一致的。
一个 Cluster 对象需要具体负责的,其实有两个工作。
**第一个工作只在该 Cluster 对象第一次被创建的时候才会执行。这个工作,就是 Bootstrap,即:创建一个单节点的种子集群。**由于种子集群只有一个节点,所以这一步直接就会生成一个 Etcd 的 Pod 对象。这个 Pod 里有一个 InitContainer,负责检查 Pod 的 DNS 记录是否正常。如果检查通过,用户容器也就是 Etcd 容器就会启动起来。这个 Etcd 容器最重要的部分,是它的启动命令。启动中,Etcd Operator 只会使用 Pod 的 DNS 记录,而不是它的 IP 地址。因为在 Operator 生成上述启动命令的时候,Etcd 的 Pod 还没有被创建出来,它的 IP 地址自然也无从谈起。
这也就意味着,每个 Cluster 对象,都会事先创建一个与该 EtcdCluster 同名的 Headless Service。这样,Etcd Operator 在接下来的所有创建 Pod 的步骤里,就都可以使用 Pod 的 DNS 记录来代替它的 IP 地址了。
Cluster 对象的第二个工作,则是启动该集群所对应的控制循环。
这个控制循环每隔一定时间,就会执行一次下面的 Diff 流程。
首先,控制循环要获取到所有正在运行的、属于这个 Cluster 的 Pod 数量,也就是该 Etcd 集群的“实际状态”。
而这个 Etcd 集群的“期望状态”,正是用户在 EtcdCluster 对象里定义的 size。
所以接下来,控制循环会对比这两个状态的差异。
如果实际的 Pod 数量不够,那么控制循环就会执行一个添加成员节点的操作(即:上述流程图中的 addOneMember 方法);反之,就执行删除成员节点的操作(即:上述流程图中的 removeOneMember 方法)。
以 addOneMember 方法为例,它执行的流程如下所示:
- 生成一个新节点的 Pod 的名字,比如:example-etcd-cluster-v6v6s6stxd;
- 调用 Etcd Client,执行 etcdctl member add example-etcd-cluster-v6v6s6stxd 命令;
- 使用这个 Pod 名字,和已经存在的所有节点列表,组合成一个新的 initial-cluster 字段的值;
- 使用这个 initial-cluster 的值,生成这个 Pod 里 Etcd 容器的启动命令。
当这个容器启动之后,一个新的 Etcd 成员节点就被加入到了集群当中。控制循环会重复这个过程,直到正在运行的 Pod 数量与 EtcdCluster 指定的 size 一致。
有了这样一个与 EtcdCluster 对象一一对应的控制循环之后,后续对这个 EtcdCluster 的任何修改,比如:修改 size 或者 Etcd 的 version,它们对应的更新事件都会由这个 Cluster 对象的控制循环进行处理。

