Linux 容器能看见“网络栈”,被隔离在它自己的 Network Namespace 当中。“网络栈”包括了:网卡(Network Interface)、回环设备(Loopback Device)、路由表(Routing Table)和 iptables 规则。对于一个进程来说,这些要素,其实就构成了它发起和响应网络请求的基本环境。
作为一个容器,它可以声明直接使用宿主机的网络栈(–net=host),即:不开启 Network Namespace
在这种情况下,这个容器启动后,直接监听的就是宿主机的 80 端口。
接使用宿主机网络栈的方式,虽然可以为容器提供良好的网络性能,但也会不可避免地引入共享网络资源的问题,比如端口冲突。所以,在大多数情况下,都希望容器进程能使用自己 Network Namespace 里的网络栈,即:拥有属于自己的 IP 地址和端口。
docker
这个被隔离的容器进程,跟其他 Network Namespace 里的容器进程进行交互可以用是网桥(Bridge),它是一个工作在数据链路层(Data Link)的设备,主要功能是根据 MAC 地址学习来将数据包转发到网桥的不同端口(Port)上。为了实现这个交互,Docker会默认在宿主机上创建一个名叫 docker0 的网桥,凡是连接在 docker0 网桥上的容器,就可以通过它来进行通信。然后可以使用Veth Pair虚拟设备将容器“连接”到 docker0 网桥上。
Veth Pair 设备的特点是:它被创建出来后,总是以两张虚拟网卡(Veth Peer)的形式成对出现的。并且,从其中一个“网卡”发出的数据包,可以直接出现在与它对应的另一张“网卡”上,哪怕这两个“网卡”在不同的 Network Namespace 里。这就使得 Veth Pair 常常被用作连接不同 Network Namespace 的“网线”。
在默认情况下,被限制在 Network Namespace 里的容器进程,实际上是通过 Veth Pair 设备 + 宿主机网桥的方式,实现了跟同其他容器的数据交换。
当你遇到容器连不通“外网”的时候,你都应该先试试 docker0 网桥能不能 ping 通,然后查看一下跟 docker0 和 Veth Pair 设备相关的 iptables 规则是不是有异常,往往就能够找到问题的答案了。
容器夸主机通信
构建容器夸主机通信的容器网络的核心在于:我们需要在已有的宿主机网络上,再通过软件构建一个覆盖在已有宿主机网络之上的、可以把所有容器连通在一起的虚拟网络。所以,这种技术就被称为:Overlay Network(覆盖网络)。
Overlay Network 本身,可以由每台宿主机上的一个“特殊网桥”共同组成。比如,当 Node 1 上的 Container 1 要访问 Node 2 上的 Container 3 的时候,Node 1 上的“特殊网桥”在收到数据包之后,能够通过某种方式,把数据包发送到正确的宿主机,比如 Node 2 上。而 Node 2 上的“特殊网桥”在收到数据包后,也能够通过某种方式,把数据包转发给正确的容器,比如 Container 3。
Flannel
Flannel 项目是 CoreOS 公司主推的容器网络方案。事实上,Flannel 项目本身只是一个框架,真正为我们提供容器网络功能的,是 Flannel 的后端实现。目前,Flannel 支持三种后端实现,分别是:
- VXLAN;
- host-gw;
- UDP。
这三种不同的后端实现,正代表了三种容器跨主网络的主流实现方法。UDP 模式,是 Flannel 项目最早支持的一种方式,却也是性能最差的一种方式。因为Flannel UDP 模式的容器通信有一个flanneld 的处理过程会使得在发出IP包的过程中,需要经过三次用户态与内核态之间的切换,这个模式目前已经被弃用。
Flannel UDP 模式的跨主通信的基本原理如图所示:
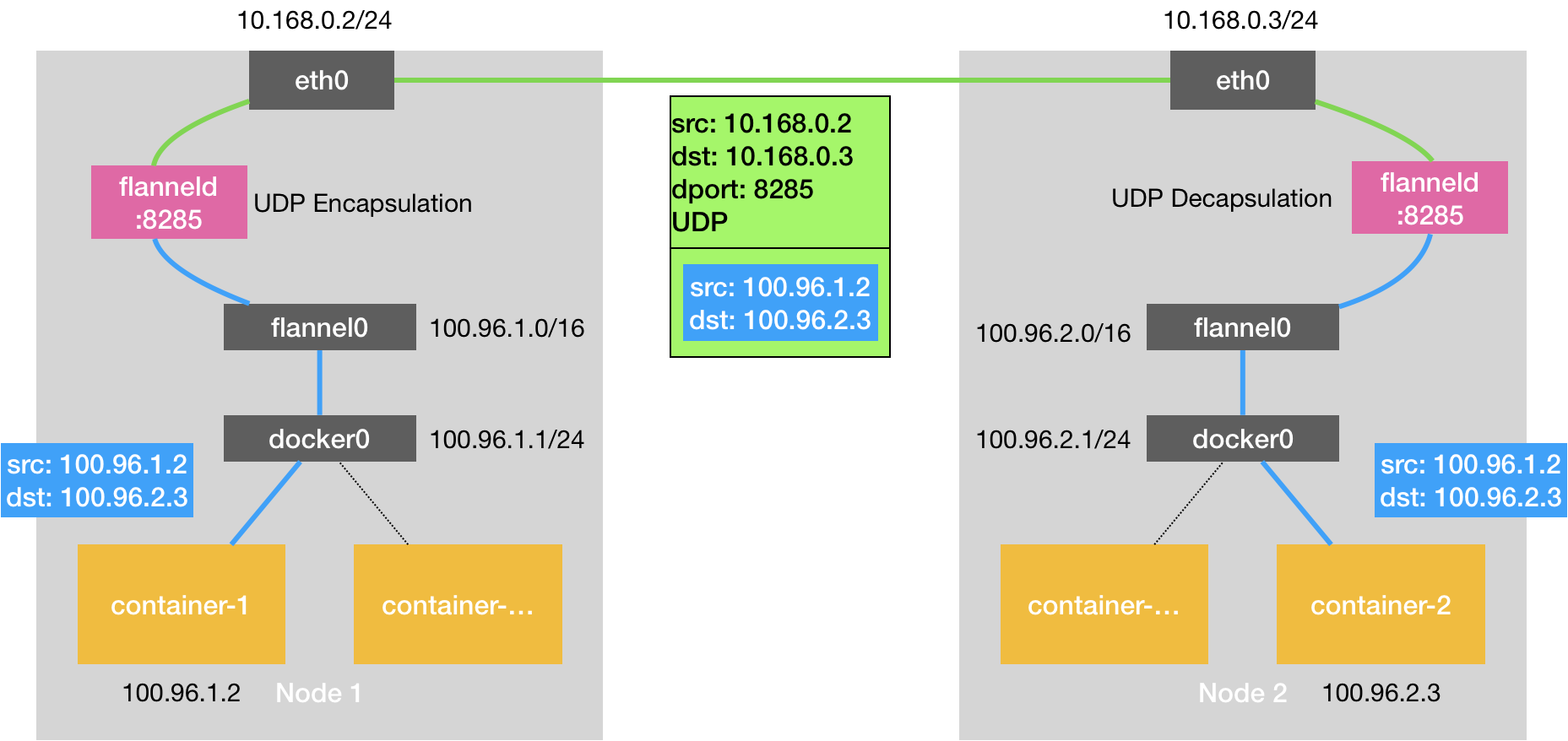
Flannel UDP 模式提供的其实是一个三层的 Overlay 网络,即:它首先对发出端的 IP 包进行 UDP 封装,然后在接收端进行解封装拿到原始的 IP 包,进而把这个 IP 包转发给目标容器。这就好比,Flannel 在不同宿主机上的两个容器之间打通了一条“隧道”,使得这两个容器可以直接使用 IP 地址进行通信,而无需关心容器和宿主机的分布情况。
VXLAN,即 Virtual Extensible LAN(虚拟可扩展局域网),是 Linux 内核本身就支持的一种网络虚似化技术。,VXLAN 可以完全在内核态实现上述封装和解封装的工作,从而通过与UDP相似的“隧道”机制,构建出覆盖网络(Overlay Network)。
VXLAN 的覆盖网络的设计思想是:在现有的三层网络之上,“覆盖”一层虚拟的、由内核 VXLAN 模块负责维护的二层网络,使得连接在这个 VXLAN 二层网络上的“主机”(虚拟机或者容器都可以)之间,可以像在同一个局域网(LAN)里那样自由通信。当然,实际上,这些“主机”可能分布在不同的宿主机上,甚至是分布在不同的物理机房里。
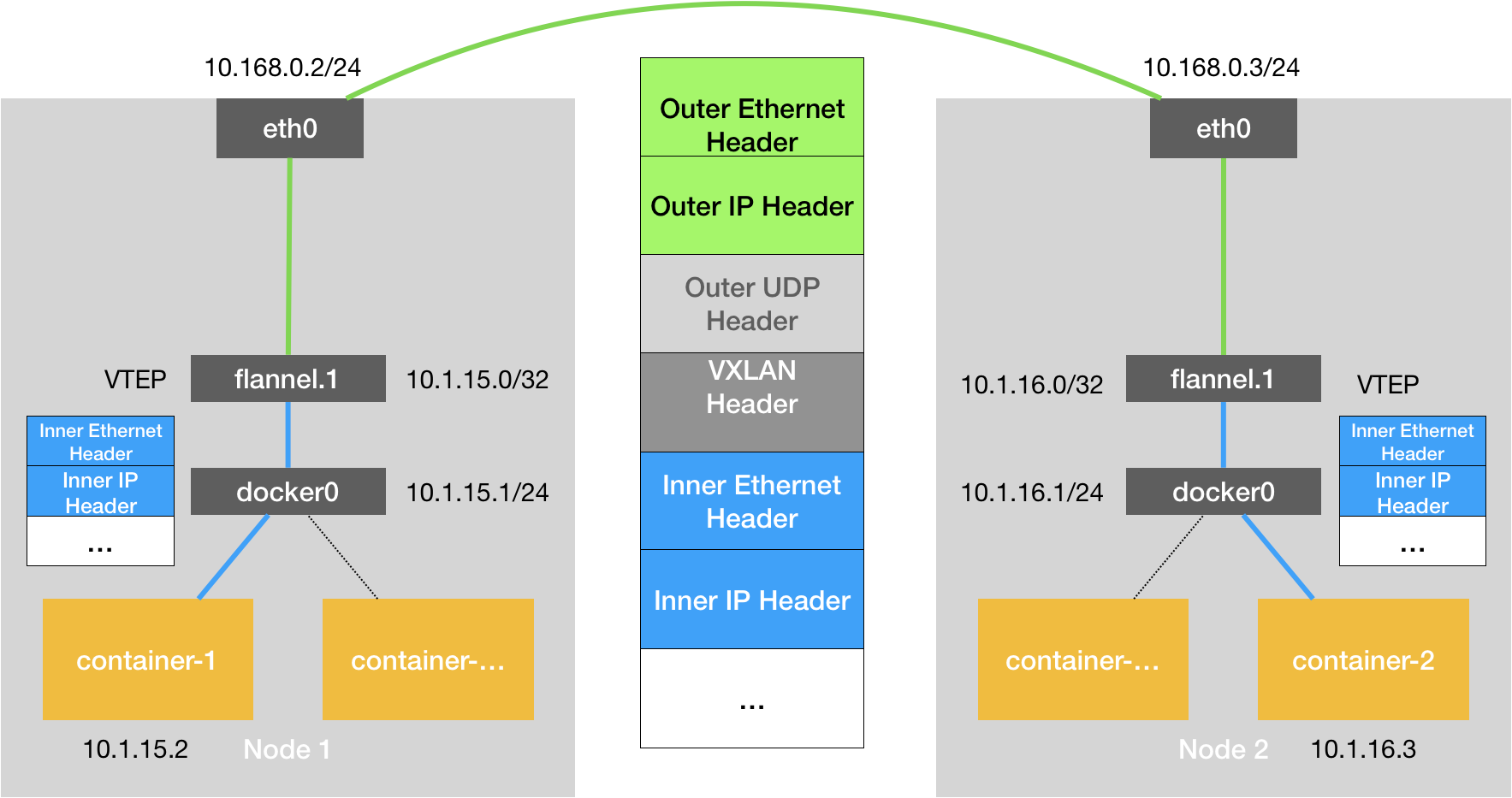
而为了能够在二层网络上打通“隧道”,VXLAN 会在宿主机上设置一个特殊的网络设备作为“隧道”的两端。这个设备就叫作 VTEP,即:VXLAN Tunnel End Point(虚拟隧道端点)。
VTEP 设备的作用,其实跟flanneld 进程非常相似。只不过,它进行封装和解封装的对象,是二层数据帧(Ethernet frame);而且这个工作的执行流程,全部是在内核里完成的(因为 VXLAN 本身就是 Linux 内核中的一个模块)。
下图展示了VTEP 设备进行“隧道”通信的流程:
CNI 网桥
Kubernetes里的CNI网桥通信的基本原理如图所示:
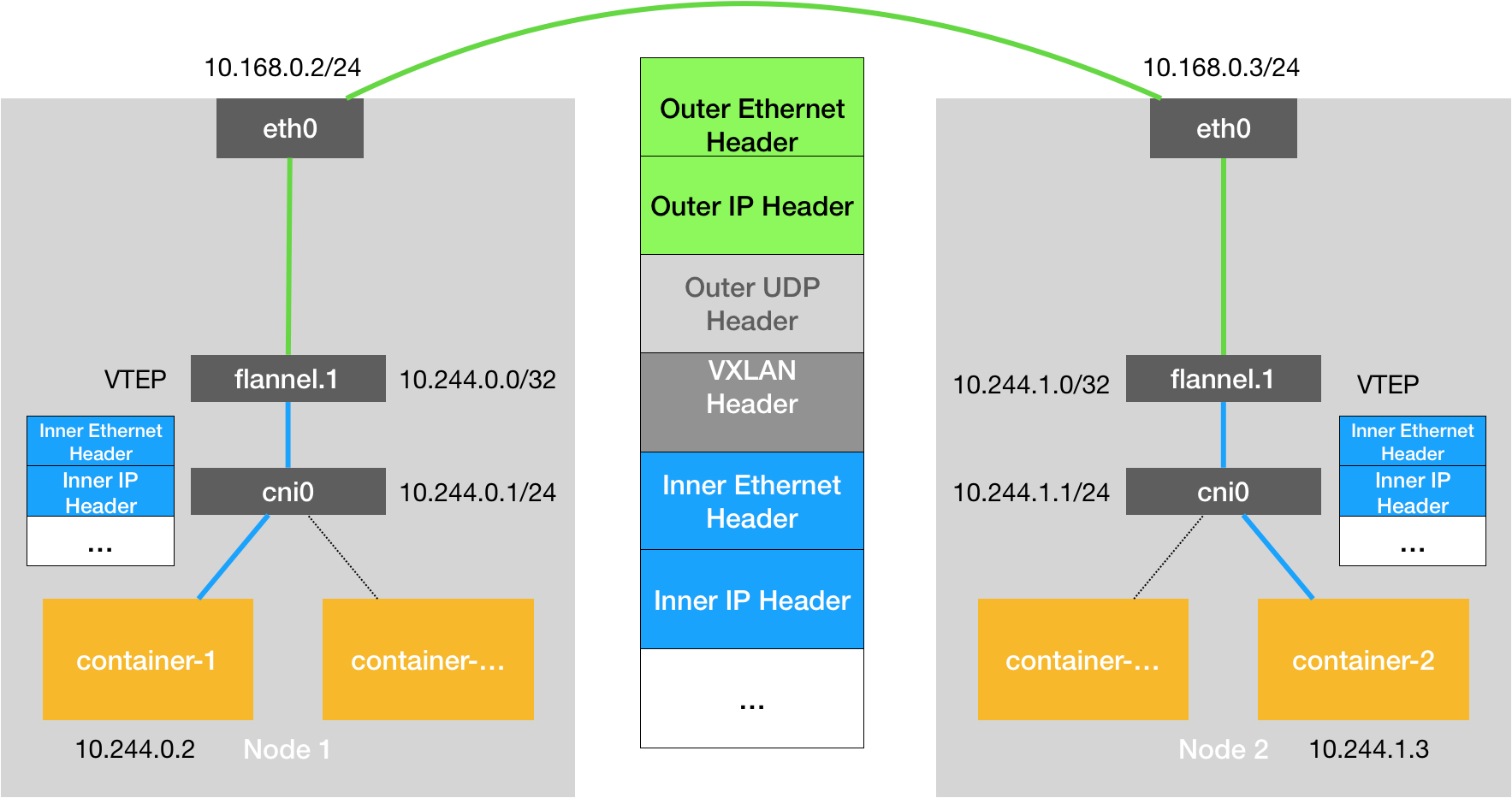
CNI 的设计思想,是:Kubernetes 在启动 Infra 容器之后,就可以直接调用 CNI 网络插件,为这个 Infra 容器的 Network Namespace,配置符合预期的网络栈。
CNI 的基础可执行文件,按照功能可以分为三类:
第一类,叫作 Main 插件,它是用来创建具体网络设备的二进制文件。比如,bridge(网桥设备)、ipvlan、loopback(lo 设备)、macvlan、ptp(Veth Pair 设备),以及 vlan。
Flannel、Weave 等项目,都属于“网桥”类型的 CNI 插件。所以在具体的实现中,它们往往会调用 bridge 这个二进制文件。
第二类,叫作 IPAM(IP Address Management)插件,它是负责分配 IP 地址的二进制文件。比如,dhcp,这个文件会向 DHCP 服务器发起请求;host-local,则会使用预先配置的 IP 地址段来进行分配。
第三类,是由 CNI 社区维护的内置 CNI 插件。比如:flannel,就是专门为 Flannel 项目提供的 CNI 插件;tuning,是一个通过 sysctl 调整网络设备参数的二进制文件;portmap,是一个通过 iptables 配置端口映射的二进制文件;bandwidth,是一个使用 Token Bucket Filter (TBF) 来进行限流的二进制文件。
要实现一个给 Kubernetes 用的容器网络方案,需要做两部分工作,以 Flannel 项目为例:
首先,实现这个网络方案本身。这一部分需要编写的,其实就是 flanneld 进程里的主要逻辑。比如,创建和配置 flannel.1 设备、配置宿主机路由、配置 ARP 和 FDB 表里的信息等等。
然后,实现该网络方案对应的 CNI 插件。这一部分主要需要做的,就是配置 Infra 容器里面的网络栈,并把它连接在 CNI 网桥上。
Kubernetes 三层网络方案
下图展示了 Flannel 的 host-gw 模式的工作原理:

host-gw 模式的工作原理,其实就是将每个 Flannel 子网(Flannel Subnet,比如:10.244.1.0/24)的“下一跳”,设置成了该子网对应的宿主机的 IP 地址。
也就是说,这台“主机”(Host)会充当这条容器通信路径里的“网关”(Gateway)。这也正是“host-gw”的含义。
Flannel 子网和主机的信息,都是保存在 Etcd 当中的。flanneld 只需要 WACTH 这些数据的变化,然后实时更新路由表即可。
而在这种模式下,容器通信的过程就免除了额外的封包和解包带来的性能损耗。根据实际的测试,host-gw 的性能损失大约在 10% 左右,而其他所有基于 VXLAN“隧道”机制的网络方案,性能损失都在 20%~30% 左右。
host-gw 模式能够正常工作的核心,就在于 IP 包在封装成帧发送出去的时候,会使用路由表里的“下一跳”来设置目的 MAC 地址。这样,它就会经过二层网络到达目的宿主机。所以说,Flannel host-gw 模式必须要求集群宿主机之间是二层连通的。
Calico
**相比于Flannel 通过 Etcd 和宿主机上的 flanneld 来维护路由信息的做法,Calico 项目使用了一个“重型武器”来自动地在整个集群中分发路由信息。**这个“重型武器”,就是 BGP
BGP 的全称是 Border Gateway Protocol,即:边界网关协议。它是一个 Linux 内核原生就支持的、专门用在大规模数据中心里维护不同的“自治系统”之间路由信息的、无中心的路由协议。
自治系统运行原理如下图所示:
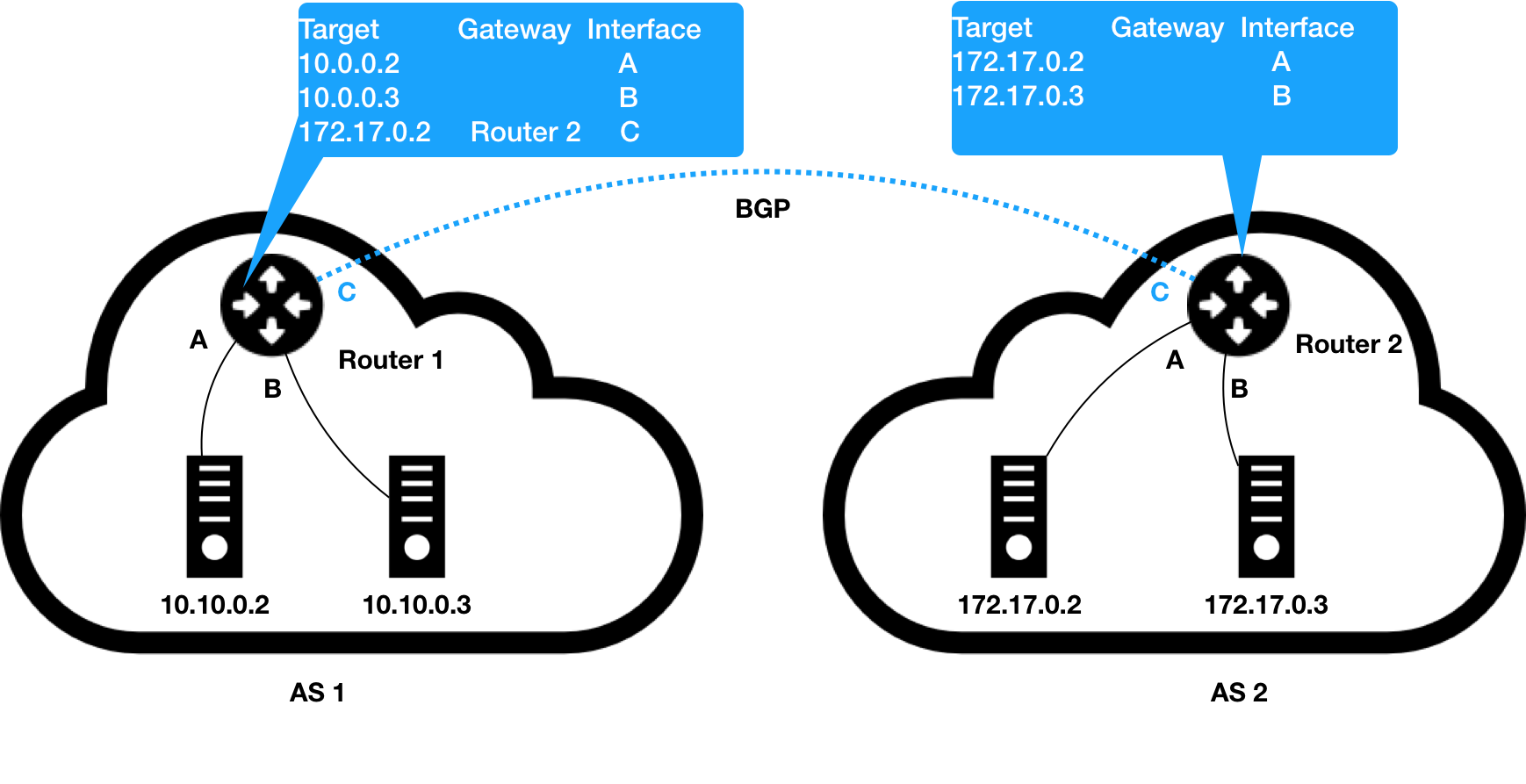
在这个图中,我们有两个自治系统(Autonomous System,简称为 AS):AS 1 和 AS 2。而所谓的一个自治系统,指的是一个组织管辖下的所有 IP 网络和路由器的全体。你可以把它想象成一个小公司里的所有主机和路由器。在正常情况下,自治系统之间不会有任何“来往”。
但是,如果这样两个自治系统里的主机,要通过 IP 地址直接进行通信,我们就必须使用路由器把这两个自治系统连接起来。
负责把自治系统连接在一起的路由器,我们就把它形象地称为:边界网关。它跟普通路由器的不同之处在于,它的路由表里拥有其他自治系统里的主机路由信息。
BGP在面对由成千上万个主机、无数个路由器,甚至是由多个公司、多个网络提供商、多个自治系统组成的复合自治系统有着天然的优势。
使用了 BGP 之后,你可以认为,在每个边界网关上都会运行着一个小程序,它们会将各自的路由表信息,通过 TCP 传输给其他的边界网关。而其他边界网关上的这个小程序,则会对收到的这些数据进行分析,然后将需要的信息添加到自己的路由表里。
BGP,就是在大规模网络中实现节点路由信息共享的一种协议。
BGP 的这个能力,正好可以取代 Flannel 维护主机上路由表的功能。而且,BGP 这种原生就是为大规模网络环境而实现的协议,其可靠性和可扩展性,远非 Flannel 自己的方案可比。
Calico 项目的架构由三个部分组成:
- Calico 的 CNI 插件。这是 Calico 与 Kubernetes 对接的部分。我已经在上一篇文章中,和你详细分享了 CNI 插件的工作原理,这里就不再赘述了。
- Felix。它是一个 DaemonSet,负责在宿主机上插入路由规则(即:写入 Linux 内核的 FIB 转发信息库),以及维护 Calico 所需的网络设备等工作。
- BIRD。它就是 BGP 的客户端,专门负责在集群里分发路由规则信息。
除了对路由信息的维护方式之外,Calico 项目与 Flannel 的 host-gw 模式的另一个不同之处,就是它不会在宿主机上创建任何网桥设备。
Calico 工作原理如图:

其中的绿色实线标出的路径,就是一个 IP 包从 Node 1 上的 Container 1,到达 Node 2 上的 Container 4 的完整路径。
可以看到,Calico 的 CNI 插件会为每个容器设置一个 Veth Pair 设备,然后把其中的一端放置在宿主机上(它的名字以 cali 前缀开头)。
由于 Calico 没有使用 CNI 的网桥模式,Calico 的 CNI 插件还需要在宿主机上为每个容器的 Veth Pair 设备配置一条路由规则,用于接收传入的 IP 包。
有了这样的 Veth Pair 设备之后,容器发出的 IP 包就会经过 Veth Pair 设备出现在宿主机上。然后,宿主机网络栈就会根据路由规则的下一跳 IP 地址,把它们转发给正确的网关。接下来的流程就跟 Flannel host-gw 模式完全一致了。
这里最核心的“下一跳”路由规则,就是由 Calico 的 Felix 进程负责维护的。这些路由规则信息,则是通过 BGP Client 也就是 BIRD 组件,使用 BGP 协议传输而来的。
Calico 项目实际上将集群里的所有节点,都当作是边界路由器来处理,它们一起组成了一个全连通的网络,互相之间通过 BGP 协议交换路由规则。这些节点,称为 BGP Peer。
Calico 维护的网络在默认配置下,是一个被称为“Node-to-Node Mesh”的模式。这时候,每台宿主机上的 BGP Client 都需要跟其他所有节点的 BGP Client 进行通信以便交换路由信息。但是,随着节点数量 N 的增加,这些连接的数量就会以 N²的规模快速增长,从而给集群本身的网络带来巨大的压力。Node-to-Node Mesh 模式一般推荐用在少于 100 个节点的集群里。而在更大规模的集群中,你需要用到的是一个叫作 Route Reflector 的模式。在这种模式下,Calico 会指定一个或者几个专门的节点,来负责跟所有节点建立 BGP 连接从而学习到全局的路由规则。而其他节点,只需要跟这几个专门的节点交换路由信息,就可以获得整个集群的路由规则信息了。这些专门的节点,就是所谓的 Route Reflector 节点,它们实际上扮演了“中间代理”的角色,从而把 BGP 连接的规模控制在 N 的数量级上。
soft multi-tenancy
Kubernetes 的网络模型只关注容器之间网络的“连通”,并不关心容器之间网络的“隔离”。这跟传统的 IaaS 层的网络方案,区别非常明显。
在 Kubernetes 里,网络隔离能力的定义,是依靠一种专门的 API 对象来描述的,即:NetworkPolicy。Kubernetes 里的 Pod 默认都是“允许所有”(Accept All)的,即:Pod 可以接收来自任何发送方的请求;或者,向任何接收方发送请求。而如果你要对这个情况作出限制,就必须通过 NetworkPolicy 对象来指定。
在YAML文件中如果把podSelector字段留空:
1 | spec: |
那么这个 NetworkPolicy 就会作用于当前 Namespace 下的所有 Pod。一旦 Pod 被 NetworkPolicy 选中,那么这个 Pod 就会进入“拒绝所有”(Deny All)的状态,即:这个 Pod 既不允许被外界访问,也不允许对外界发起访问。
NetworkPolicy 定义的规则,其实就是“白名单”
NetworkPolicy 指定的隔离规则如下所示:
- 该隔离规则只对 default Namespace 下的,携带了 role=db 标签的 Pod 有效。限制的请求类型包括 ingress(流入)和 egress(流出)。
- Kubernetes 会拒绝任何访问被隔离 Pod 的请求,除非这个请求来自于“白名单”里的对象,并且访问的是被隔离 Pod 的指定端口。
- default Namespace 里的,携带了 role=fronted 标签的 Pod;
- 任何 Namespace 里的、携带了 project=myproject 标签的 Pod;
- 任何源地址属于 172.17.0.0/16 网段,且不属于 172.17.1.0/24 网段的请求。
- Kubernetes 会拒绝被隔离 Pod 对外发起任何请求,除非请求的目的地址属于 10.0.0.0/24 网段,并且访问的是该网段地址的 5978 端口。
Kubernetes 网络插件对 Pod 进行隔离,其实是靠在宿主机上生成 NetworkPolicy 对应的 iptable 规则来实现的。
iptables 是一个操作 Linux 内核 Netfilter 子系统的“界面”。顾名思义,Netfilter 子系统的作用,就是 Linux 内核里挡在“网卡”和“用户态进程”之间的一道“防火墙”。它们的关系,可以用如下的示意图来表示:
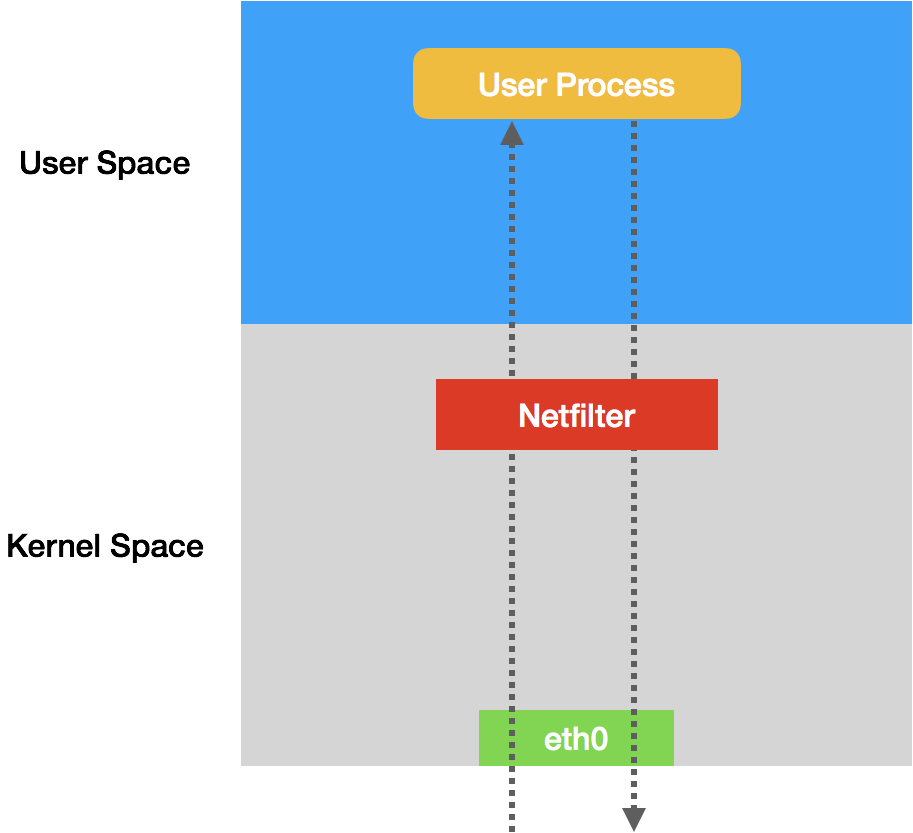
这幅示意图中,IP 包“一进一出”的两条路径上,有几个关键的“检查点”,它们正是 Netfilter 设置“防火墙”的地方。在 iptables 中,这些“检查点”被称为:链(Chain)。这是因为这些“检查点”对应的 iptables 规则,是按照定义顺序依次进行匹配的。这些“检查点”的具体工作原理,可以用如下所示的示意图进行描述:
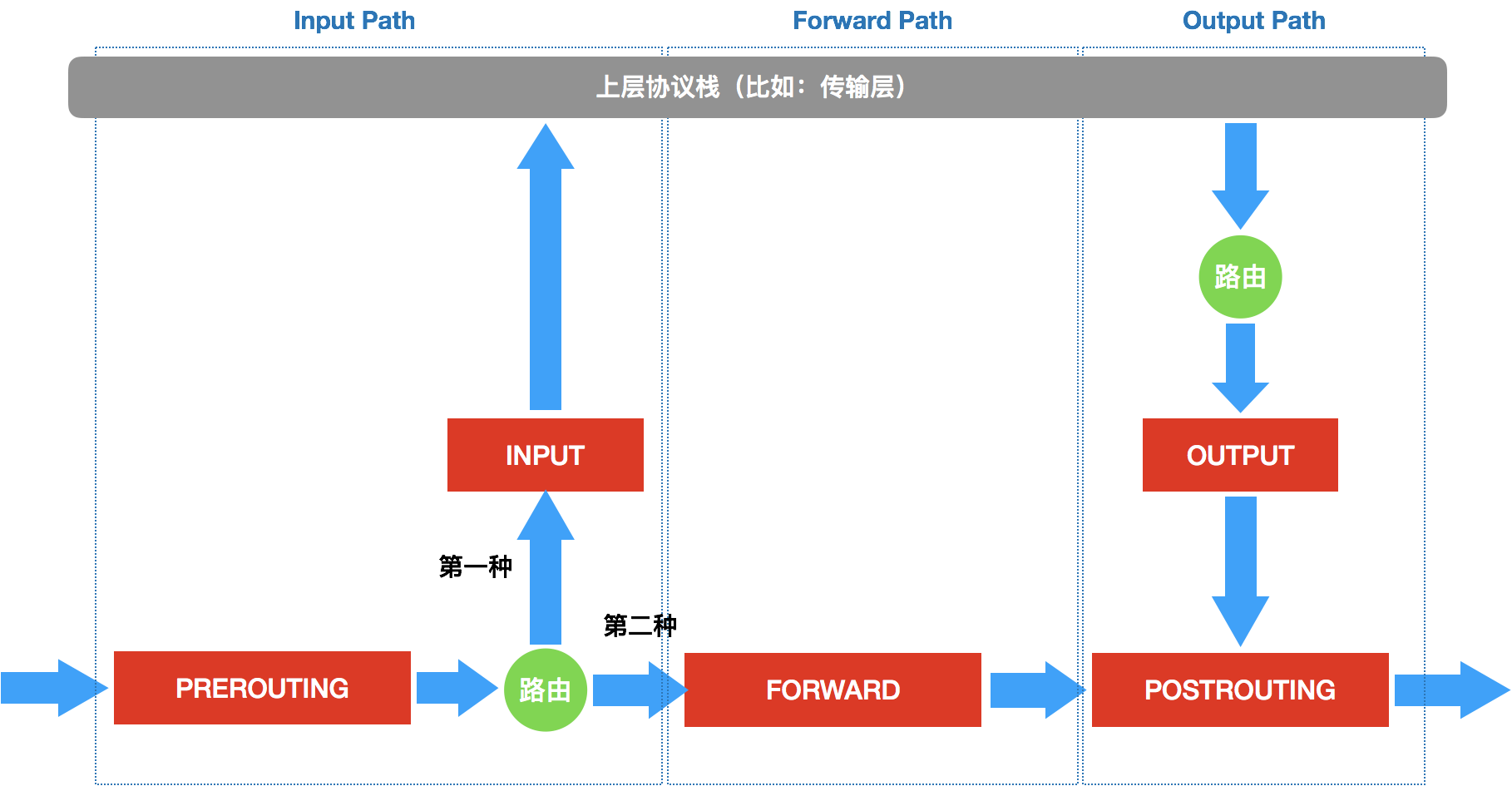
当一个 IP 包通过网卡进入主机之后,它就进入了 Netfilter 定义的流入路径(Input Path)里。在这个路径中,IP 包要经过路由表路由来决定下一步的去向。而在这次路由之前,Netfilter 设置了一个名叫 PREROUTING 的“检查点”。在 Linux 内核的实现里,所谓“检查点”实际上就是内核网络协议栈代码里的 Hook(比如,在执行路由判断的代码之前,内核会先调用 PREROUTING 的 Hook)。
经过路由之后,IP 包的去向分为了两种:
- 第一种,继续在本机处理;
- 第二种,被转发到其他目的地。
IP 包的第一种去向: 包将继续向上层协议栈流动。在它进入传输层之前,Netfilter 会设置一个名叫 INPUT 的“检查点”。到这里,IP 包流入路径(Input Path)结束。
接下来,这个 IP 包通过传输层进入用户空间,交给用户进程处理。而处理完成后,用户进程会通过本机发出返回的 IP 包。这时候,这个 IP 包就进入了流出路径(Output Path)。
此时,IP 包首先还是会经过主机的路由表进行路由。路由结束后,Netfilter 就会设置一个名叫 OUTPUT 的“检查点”。然后,在 OUTPUT 之后,再设置一个名叫 POSTROUTING“检查点”。
IP 包的第二种去向:IP 包不会进入传输层,而是会继续在网络层流动,从而进入到转发路径(Forward Path)。在转发路径中,Netfilter 会设置一个名叫 FORWARD 的“检查点”。
在 FORWARD“检查点”完成后,IP 包就会来到流出路径。而转发的 IP 包由于目的地已经确定,它就不会再经过路由,也自然不会经过 OUTPUT,而是会直接来到 POSTROUTING“检查点”。
POSTROUTING 的作用,其实就是上述两条路径,最终汇聚在一起的“最终检查点”。
在有网桥参与的情况下,上述 Netfilter 设置“检查点”的流程,实际上也会出现在链路层(二层),并且会跟我在上面讲述的网络层(三层)的流程有交互。
这些链路层的“检查点”对应的操作界面叫作 ebtables。所以,准确地说,数据包在 Linux Netfilter 子系统里完整的流动过程,其实应该如下所示
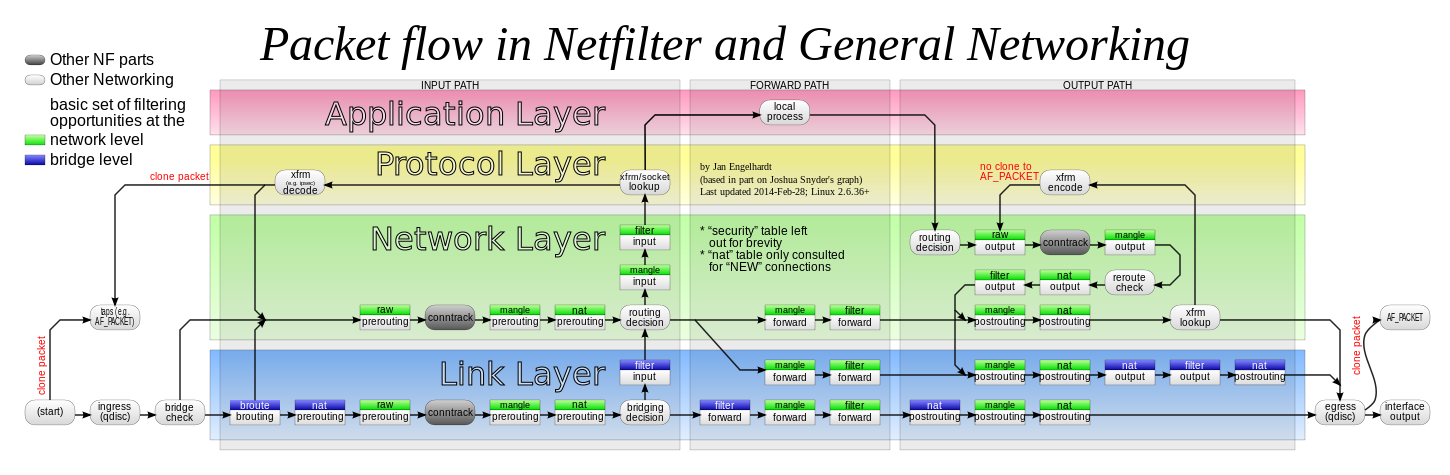
iptables 表的作用,就是在某个具体的“检查点”(比如 Output)上,按顺序执行几个不同的检查动作(比如,先执行 nat,再执行 filter)。

